Was ist die robots.txt-Datei?
Die robots.txt ist eine Datei im Stamm-Verzeichnis deiner Website, in der du Suchmaschinen sagst, welche Bereiche gecrawlt werden dürfen und welche nicht.
Stell dir die robots.txt-Datei wie eine Art Türsteher deiner Webseite vor, der entscheidet, welche Bereiche deiner Webseite besucht werden dürfen, welche Bereich blockiert sind und wer rein darf.
Gut zu wissen
Auch blockierte Seiten können theoretisch indexiert werden, wenn Google sie über andere Wege (z.B. externe Links) findet. Und nicht jeder Crawler hält sich an die Regeln (v. a. Bots, die nichts Gutes im Sinn haben).
Was bedeutet die Meldung „Durch robots.txt-Datei blockiert“?
Diese Meldung bedeutet, dass Google die URL zwar sieht, aber nicht crawlen darf, weil sie in der robots.txt-Datei blockiert wurde.
Wenn eine URL in der robots.txt blockiert ist, heißt das:
- Google kennt die URL
- Google darf sie aber nicht besuchen
- Google kann deshalb keine Inhalte abrufen
- Die Indexierung ist je nach Situation möglich, aber eingeschränkt
Wie erkennt man betroffene Seiten?
Um herauszufinden, welche URLs von „Durch robots.txt-Datei blockiert“ betroffen sind, gehst du am besten so vor:
- Öffne in der GSC den Bereich Indexierung → Seiten. Dort findest du unter „Warum Seiten nicht indexiert werden“ die Meldung: „Durch robots.txt-Datei blockiert“
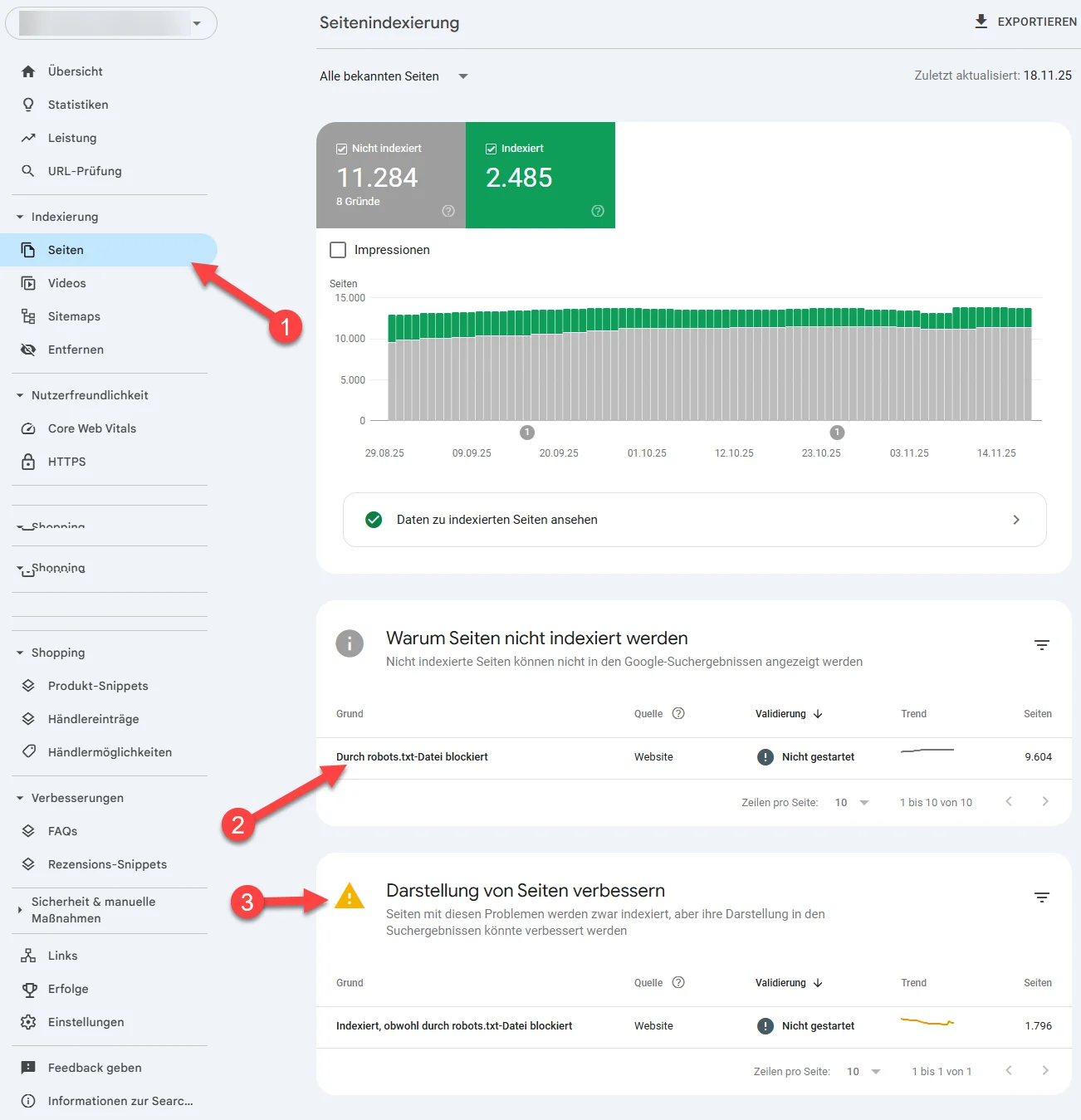
In unserem Fall befindet sich ein weiterer Eintrag (3): „Darstellung von Seiten verbessern → Indexiert, obwohl durch robots.txt-Datei blockiert“
Das bedeutet:
- Die Seite ist indexiert,
- …aber Google konnte sie nicht vollständig crawlen,
- …weil sie durch die robots.txt blockiert ist.
Das passiert häufig bei URLs mit Parametern wie: ?add-to-cart= oder Filter ?orderby=
Diese Seiten sollten fast immer blockiert bleiben, denn sie gehören nicht in den Index und sind nur funktionale URLs.
- Eine betroffene URL prüfen: Crawling erlaubt? Seitenaufruf erfolgreich?
Wenn du auf die “Fehlermeldung” klickst, erscheint die Auflistung der betroffenen URLs.
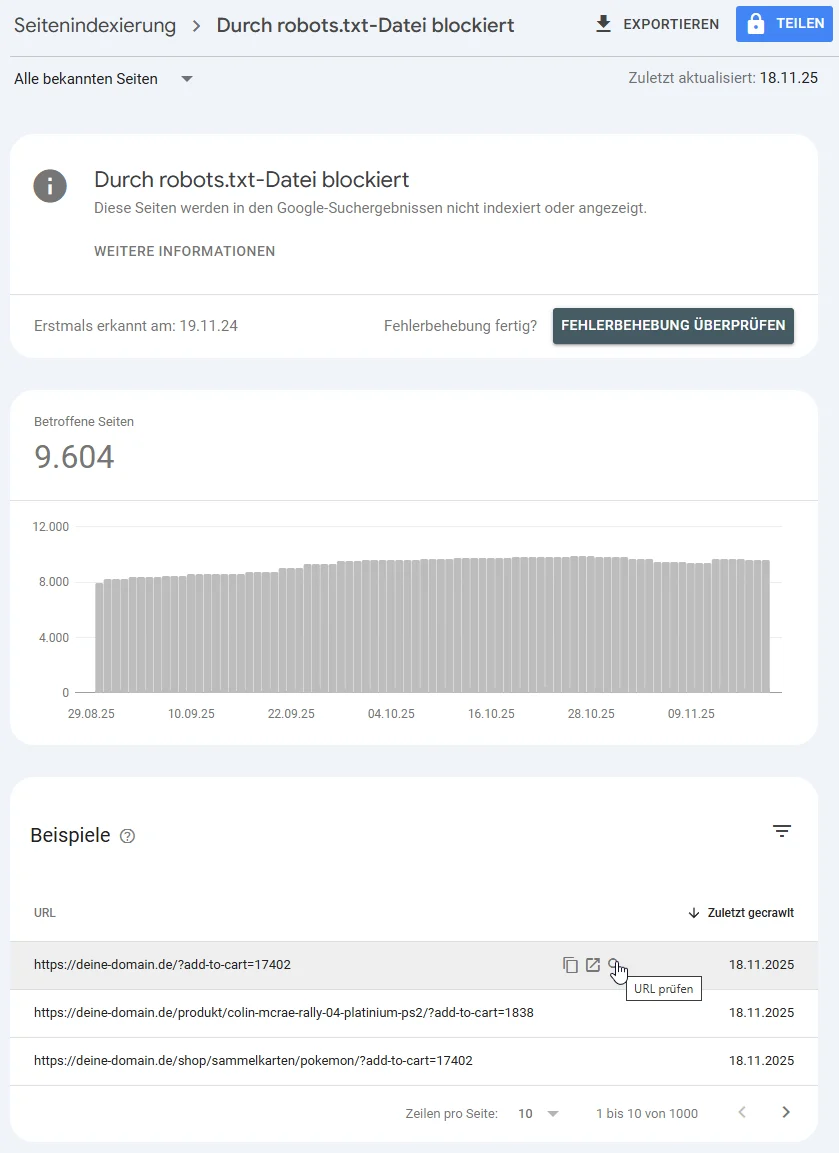
Klickst du auf die Lupe neben einer URL, öffnet sich der URL-Prüfbericht.
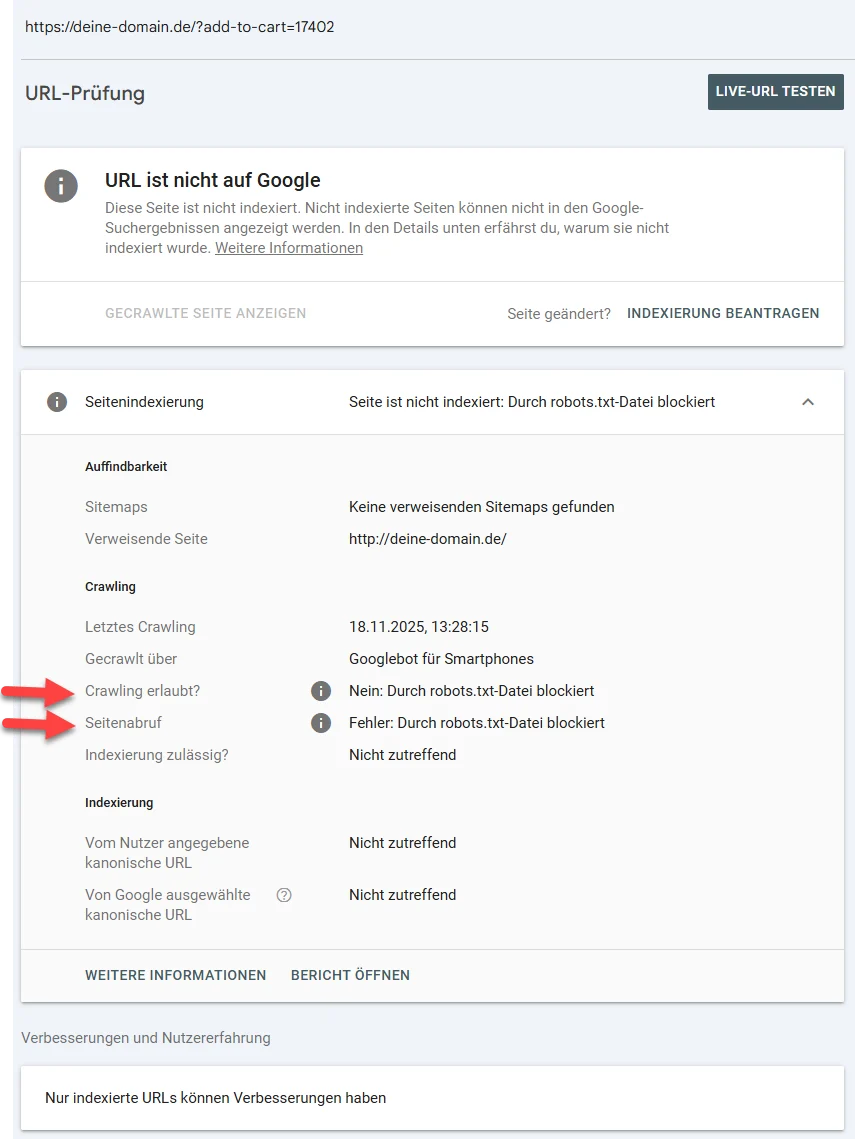
Hier zeigen zwei Felder genau, was los ist:
- Crawling erlaubt? → Nein: Durch robots.txt-Datei blockiert
- Seitenaufruf → Fehler: Durch robots.txt-Datei blockiert
Das bedeutet:
Google sieht die URL, kann sie aber nicht aufrufen.
Typische Beispiele:
/cart//checkout//my-account//wp-admin/- Suchergebnisseiten
/?s=... - Filter-/Parameterseiten
?add-to-cart=
Diese gehören nicht in den Index und sollen blockiert bleiben.
Warum kann das passieren?
Die Meldung „Durch robots.txt-Datei blockiert“ entsteht aus verschiedenen Gründen und viele davon sind bewusst so gewollt oder ganz normal. Google hält sich in diesem Fall einfach an die Regeln, die du (oder dein System) ihm gegeben hast.
Hier die häufigsten Ursachen:
1. Die URL wurde bewusst blockiert
Das ist der Normalfall. Viele Bereiche einer Website sollen gar nicht gecrawlt werden, z. B.:
- Warenkorb (
/cart/) - Checkout (
/checkout/) - Kundenkonto (
/my-account/) - interne Suchseiten (
/?s=) - Shop-, Filter- und Sortierparameter (
?add-to-cart=,?orderby=) - technische Verzeichnisse (
/wp-json/,/cgi-bin/)
Diese URLs wären im Index völlig sinnlos, also blockiert man sie.
Oft tauchen auch PDFs, Marketingseiten oder interne Verzeichnisstrukturen hier auf, weil sie bewusst vom Crawling ausgeschlossen wurden.
2. Die URL existiert, ist aber nicht für die Öffentlichkeit gedacht
Das betrifft zum Beispiel:
- alte Testumgebungen
- Staging-Ordner
- temporäre Uploads
- verwaiste Landingpages
- Tracking-Parameter aus Ads, Social Media oder Newslettern
Google entdeckt die URL trotzdem (z. B. über Backlinks, Ads oder Social), darf sie aber nicht abrufen.
3. Indexiert, obwohl durch robots.txt-Datei blockiert
Die Google Search Console zeigt manchmal folgenden Hinweis:
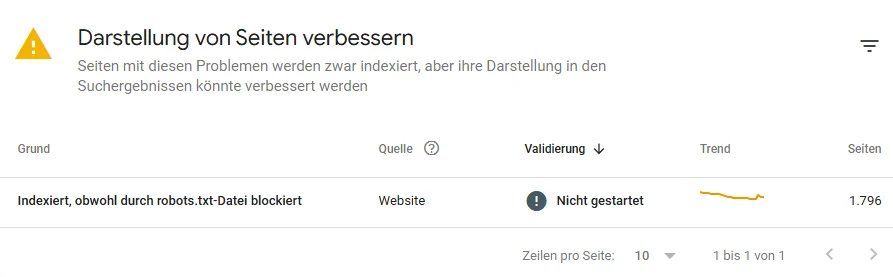
In der Praxis entsteht dieser Hinweis jedoch sehr häufig bei URLs, die:
- gar nicht indexiert sind,
- nicht indexiert sein sollen, und
- ein Canonical auf die richtige Seite haben.
Das ist etwas wiedersprüchlich, denn was Google da schreibt, das stimmt in vielen Fällen nicht!
Es gibt jedoch Fälle, bei denen die Meldung korrekt ist:
- Eine Seite war früher indexiert, wurde später blockiert
- Eine PDF wurde indexiert, später aber ausgeschlossen
- Ein komplettes Verzeichnis wird nachträglich gesperrt
- Eine externe Seite hat starke Backlinks auf eine nun blockierte URL
Das sind die Fälle, in denen Google Inhalte nicht mehr crawlen und entsprechend aktualisieren kann, was zur Einschränkung in der Suche führen kann.
4. Die Blockierung ist versehentlich entstanden
Wir haben es auch schon erlebt, dass versehentlich ganze Verzeichnisse gesperrt wurden. Zum Beispiel wenn:
- nach einem Relaunch die alte robots.txt blindlinks mitkopiert wird
- irgendwelche Staging-Einstellungen übernommen wurden
- Entwickler temporär ganze Verzeichnisse blockieren und dann vergessen
- der Klassiker: Typos bei den Befehlen (falscher Slash oder eine falsche Wildcard)
Ist das kritisch? Ja/Nein?
Die Gute Nachricht: In den meisten Fällen ist es nicht kritisch.
Natürlich gibt es aber wie immer Ausnahmen. Ein erfahrener SEO sieht diese aber in wenigen Minuten.
Wann ist es nicht kritisch?
Die meisten URLs in dieser Meldung gehören genau dorthin. Unkritisch ist die Meldung, wenn es sich um:
- Parameter-URLs handelt (
?add-to-cart=,?orderby=,?s=…) - automatisch erzeugte Shop- oder Systemseiten
- Filter-/Sortier-Parameter
- interne Suchseiten
- Warenkorb / Checkout
- technische Verzeichnisse (
/wp-json/,/feed/,/comments/feed/) - PDFs oder interne Marketingseiten
- alte Social-Media-Links oder falsch kopierte URLs
- Staging-/Test-Strukturen
Hinweis
Durch die Blockierung von PDFs oder anderen Seiten in der robots.txt lässt sich zwar das Crawling verhindern, aber die Dateien können trotzdem indexiert werden.
Wenn du die Indexierung zuverlässig ausschließen möchtest, setze für PDFs und andere nicht-HTML-Dateien einen X-Robots-Tag: noindex im HTTP-Header und für normale Seiten den Meta-Robots-Tag: noindex im <head> Bereich.
Der Clou:
Wenn du wirklich sicherstellen willst, dass eine Seite oder Datei nicht indexiert wird, dann darfst du in der robots.txt nicht das Crawling verbieten. Denn wenn Google die Inhalte nicht abrufen darf, kann es auch den noindex-Hinweis nicht sehen.
Wann kann ist es kritisch?
Generell ist es immer kritisch, wenn wichtige Landingpages, Kategorieseiten, Produktseiten, Blogbeiträge etc. blockiert werden.
Das passiert meistens nur, wenn die Disallow-Regeln in der robots.txt fehlerhaft sind.
Lösungen Schritt für Schritt
Ich möchte nochmal betonen, dass die meisten Meldungen, die unter den Punkt: Durch robots.txt-Datei blockiert fallen, nicht kritisch sind.
Wirklich relevant ist sie nur, wenn wichtige Seiten betroffen sind. Dann solltest du folgendes tun:
1. robots.txt genau prüfen
Ist eine wichtige URL betroffen, öffne die robots.txt deiner Webseite und prüfe, ob es Regeln gibt, die das crawlen der URL blockieren.
Deine robots.txt erreichst du unter folgenden Link: https://deine-domain.de/robots.txt
Randnotiz: Wenn diese leer ist, oder du keine hast, ist das auch nicht ideal.
Tool-Tipp
Wir haben eine ganze Reihe toller und kostenloser SEO Bookmarklets entwickelt und dort findest du auch eines, womit du mit einem Klick die robots.txt jeder Seite aufrufen kannst. Auch in unserem SEO Heading Checker findest du einen Direktlink zur robots.txt deiner Webseite.
2. Im Zweifel lieber einen Profi draufschauen lassen
Wenn du unsicher bist, ob deine robots.txt zu viel oder zu wenig blockiert, ob noindex, Canonical oder Weiterleitung in deinem Fall die beste Lösung ist, dann wende dich lieber an einen Experten.
Gute Entwickler, SEO-Experten oder eine SEO-Agentur wie wir sind genau für solche Fälle da.
Bonus: Blueprint robots.txt für WordPress + WooCommerce
Jetzt haben wir so viel über robots.txt geredet und du fragst dich bestimmt: Gibt es da eigentlich eine gute Vorlage?
Ja, die gibt es. Du kannst folgende Vorlage als Ausgangsbasis nutzen. Wenn du den WooCommerce Teil nicht brauchst, lösche ihn einfach raus.
Ggf. musst du den Link zur Sitemap, zur llms.txt oder auch die Suchparameter entsprechend deiner Webseite anpassen.
# Links zu deinen Sitemaps
Sitemap: https://deine-domain.de/sitemaps.xml
# Link zu deiner llms.txt
llms.txt: https://deine-domain.de/llms.txt
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
# Interne Suche blockieren
Disallow: /?s=
# WooCommerce: Parameter blockieren
Disallow: /*add-to-cart=
Disallow: /*orderby=
Disallow: /*filter=
Disallow: /*rating=
Disallow: /*price=
Disallow: /*min_price=
Disallow: /*max_price=
Disallow: /*post_type=product
# Sortierung / Pagination verhindern (nicht für SEO relevant)
Disallow: /*?paged=
# Kommentare & Feeds blockieren
Disallow: /comments/
Disallow: /comment-page-
Disallow: /*/feed/
Disallow: /feed/
# WordPress Core / technische Bereiche blockieren
Disallow: /wp-json/
Disallow: /xmlrpc.php
# Tracking- und Marketingparameter blockieren
Disallow: /*utm_
Disallow: /*fbclid=
Disallow: /*gclid=
Disallow: /*_ga=Weitere Fehlermeldungen der Google Search Console
Eine Google Fehlermeldung kommt selten allein. Hier findest du weitere Hilfestellungen zu anderen Indexierungsproblemen.


